Using PyMC3
In this assignment, we will learn how to use a library for probabilistic programming and inference called PyMC3.
Installation
Libraries that are required for this tasks can be installed with the following command (if you use PyPI):
1 | pip install pymc3 pandas numpy matplotlib seaborn |
You can also install pymc3 from source using the instruction.
1 | import numpy as np |
Grading
We will create a grader instance below and use it to collect your answers. Note that these outputs will be stored locally inside grader and will be uploaded to the platform only after running submitting function in the last part of this assignment. If you want to make a partial submission, you can run that cell anytime you want.
1 | grader = Grader() |
Task 1. Alice and Bob
Alice and Bob are trading on the market. Both of them are selling the Thing and want to get as high profit as possible.
Every hour they check out with each other’s prices and adjust their prices to compete on the market. Although they have different strategies for price setting.
Alice: takes Bob’s price during the previous hour, multiply by 0.6, add 90\$, add Gaussian noise from $N(0, 20^2)$.
Bob: takes Alice’s price during the current hour, multiply by 1.2 and subtract 20\$, add Gaussian noise from $N(0, 10^2)$.
The problem is to find the joint distribution of Alice and Bob’s prices after many hours of such an experiment.
Task 1.1
Implement the run_simulation function according to the description above.
1 | with pm.Model(): |
1 | alice_prices, bob_prices = run_simulation(alice_start_price=300, bob_start_price=300, seed=42, num_hours=3, burnin=1) |
Current answer for task 1.1 (Alice trajectory) is: 279.93428306022463 291.67686875834846
Current answer for task 1.1 (Bob trajectory) is: 314.5384966605577 345.2425410740984
Task 1.2
What is the average prices for Alice and Bob after the burnin period? Whose prices are higher?
1 | #### YOUR CODE HERE #### |
Current answer for task 1.2 (Alice mean) is: 278.85416992423353
Current answer for task 1.2 (Bob mean) is: 314.6064116545574
Task 1.3
Let’s look at the 2-d histogram of prices, computed using kernel density estimation.
1 | data = np.array(run_simulation()) |
<seaborn.axisgrid.JointGrid at 0x7ff3b55d01d0>

Clearly, the prices of Bob and Alce are highly correlated. What is the Pearson correlation coefficient of Alice and Bob prices?
1 | #### YOUR CODE HERE #### |
Current answer for task 1.3 (Bob and Alice prices correlation) is: 0.9636099866766943
Task 1.4
We observe an interesting effect here: seems like the bivariate distribution of Alice and Bob prices converges to a correlated bivariate Gaussian distribution.
Let’s check, whether the results change if we use different random seed and starting points.
1 | a_prices, b_prices = run_simulation(alice_start_price=1000.0, bob_start_price=1000.0, seed=334, num_hours=10000, burnin=1000) |
array([[1. , 0.96392419],
[0.96392419, 1. ]])
1 | # Pick different starting prices, e.g 10, 1000, 10000 for Bob and Alice. |
Current answer for task 1.4 (depends on the random data or not) is: Does not depend on random seed and starting prices
Task 2. Logistic regression with PyMC3
Logistic regression is a powerful model that allows you to analyze how a set of features affects some binary target label. Posterior distribution over the weights gives us an estimation of the influence of each particular feature on the probability of the target being equal to one. But most importantly, posterior distribution gives us the interval estimates for each weight of the model. This is very important for data analysis when you want to not only provide a good model but also estimate the uncertainty of your conclusions.
In this task, we will learn how to use PyMC3 library to perform approximate Bayesian inference for logistic regression.
This part of the assignment is based on the logistic regression tutorial by Peadar Coyle and J. Benjamin Cook.
Logistic regression.
The problem here is to model how the probability that a person has salary $\geq$ \$50K is affected by his/her age, education, sex and other features.
Let $y_i = 1$ if i-th person’s salary is $\geq$ \$50K and $y_i = 0$ otherwise. Let $x_{ij}$ be $j$-th feature of $i$-th person.
Logistic regression models this probabilty in the following way:
$$p(y_i = 1 \mid \beta) = \sigma (\beta_1 x_{i1} + \beta_2 x_{i2} + \dots + \beta_k x_{ik} ), $$
where $\sigma(t) = \frac1{1 + e^{-t}}$
Odds ratio.
Let’s try to answer the following question: does a gender of a person affects his or her salary? To do it we will use the concept of odds .
If we have a binary random variable $y$ (which may indicate whether a person makes \$50K) and if the probabilty of the positive outcome $p(y = 1)$ is for example 0.8, we will say that the odds are 4 to 1 (or just 4 for short), because succeding is 4 time more likely than failing $\frac{p(y = 1)}{p(y = 0)} = \frac{0.8}{0.2} = 4$.
Now, let’s return to the effect of gender on the salary. Let’s compute the ratio between the odds of a male having salary $\geq $ \$50K and the odds of a female (with the same level of education, experience and everything else) having salary $\geq$ \$50K. The first feature of each person in the dataset is the gender. Specifically, $x_{i1} = 0$ if the person is female and $x_{i1} = 1$ otherwise. Consider two people $i$ and $j$ having all but one features the same with the only difference in $x_{i1} \neq x_{j1}$.
If the logistic regression model above estimates the probabilities exactly, the odds for a male will be (check it!):
$$
\frac{p(y_i = 1 \mid x_{i1}=1, x_{i2}, \ldots, x_{ik})}{p(y_i = 0 \mid x_{i1}=1, x_{i2}, \ldots, x_{ik})} = \frac{\sigma(\beta_1 + \beta_2 x_{i2} + \ldots)}{1 - \sigma(\beta_1 + \beta_2 x_{i2} + \ldots)} = \exp(\beta_1 + \beta_2 x_{i2} + \ldots)
$$
Now the ratio of the male and female odds will be:
$$
\frac{\exp(\beta_1 \cdot 1 + \beta_2 x_{i2} + \ldots)}{\exp(\beta_1 \cdot 0 + \beta_2 x_{i2} + \ldots)} = \exp(\beta_1)
$$
So given the correct logistic regression model, we can estimate odds ratio for some feature (gender in this example) by just looking at the corresponding coefficient. But of course, even if all the logistic regression assumptions are met we cannot estimate the coefficient exactly from real-world data, it’s just too noisy. So it would be really nice to build an interval estimate, which would tell us something along the lines “with probability 0.95 the odds ratio is greater than 0.8 and less than 1.2, so we cannot conclude that there is any gender discrimination in the salaries” (or vice versa, that “with probability 0.95 the odds ratio is greater than 1.5 and less than 1.9 and the discrimination takes place because a male has at least 1.5 higher probability to get >$50k than a female with the same level of education, age, etc.”). In Bayesian statistics, this interval estimate is called credible interval .
Unfortunately, it’s impossible to compute this credible interval analytically. So let’s use MCMC for that!
Credible interval
A credible interval for the value of $\exp(\beta_1)$ is an interval $[a, b]$ such that $p(a \leq \exp(\beta_1) \leq b \mid X_{\text{train}}, y_{\text{train}})$ is $0.95$ (or some other predefined value). To compute the interval, we need access to the posterior distribution $p(\exp(\beta_1) \mid X_{\text{train}}, y_{\text{train}})$.
Lets for simplicity focus on the posterior on the parameters $p(\beta_1 \mid X_{\text{train}}, y_{\text{train}})$ since if we compute it, we can always find $[a, b]$ such that $p(\log a \leq \beta_1 \leq \log b \mid X_{\text{train}}, y_{\text{train}}) = p(a \leq \exp(\beta_1) \leq b \mid X_{\text{train}}, y_{\text{train}}) = 0.95$
Task 2.1 MAP inference
Let’s read the dataset. This is a post-processed version of the UCI Adult dataset.
1 | data = pd.read_csv("adult_us_postprocessed.csv") |
| sex | age | educ | hours | income_more_50K | |
|---|---|---|---|---|---|
| 0 | Male | 39 | 13 | 40 | 0 |
| 1 | Male | 50 | 13 | 13 | 0 |
| 2 | Male | 38 | 9 | 40 | 0 |
| 3 | Male | 53 | 7 | 40 | 0 |
| 4 | Female | 28 | 13 | 40 | 0 |
Each row of the dataset is a person with his (her) features. The last column is the target variable $y$. 1 indicates that this person’s annual salary is more than $50K.
First of all let’s set up a Bayesian logistic regression model (i.e. define priors on the parameters $\alpha$ and $\beta$ of the model) that predicts the value of “income_more_50K” based on person’s age and education:
$$
p(y = 1 \mid \alpha, \beta_1, \beta_2) = \sigma(\alpha + \beta_1 x_1 + \beta_2 x_2) \
\alpha \sim N(0, 100^2) \
\beta_1 \sim N(0, 100^2) \
\beta_2 \sim N(0, 100^2), \
$$
where $x_1$ is a person’s age, $x_2$ is his/her level of education, y indicates his/her level of income, $\alpha$, $\beta_1$ and $\beta_2$ are paramters of the model.
1 | with pm.Model() as manual_logistic_model: |
logp = -18,844, ||grad|| = 57,293: 100%|██████████| 30/30 [00:00<00:00, 162.41it/s]
{'a': array(-6.74811924), 'b1': array(0.04348316), 'b2': array(0.36210805)}
Sumbit MAP estimations of corresponding coefficients:
1 | with pm.Model() as logistic_model: |
logp = -15,131, ||grad|| = 0.024014: 100%|██████████| 32/32 [00:00<00:00, 190.40it/s]
{'Intercept': array(-6.7480998), 'age': array(0.04348259), 'educ': array(0.36210894)}
1 | beta_age_coefficient = map_estimate['age'] ### TYPE MAP ESTIMATE OF THE AGE COEFFICIENT HERE ### |
Current answer for task 2.1 (MAP for age coef) is: 0.043482589526144325
Current answer for task 2.1 (MAP for aducation coef) is: 0.3621089416949501
Task 2.2 MCMC
To find credible regions let’s perform MCMC inference.
1 | # You will need the following function to visualize the sampling process. |
Metropolis-Hastings
Let’s use Metropolis-Hastings algorithm for finding the samples from the posterior distribution.
Once you wrote the code, explore the hyperparameters of Metropolis-Hastings such as the proposal distribution variance to speed up the convergence. You can use plot_traces function in the next cell to visually inspect the convergence.
You may also use MAP-estimate to initialize the sampling scheme to speed things up. This will make the warmup (burnin) period shorter since you will start from a probable point.
1 | with pm.Model() as logistic_model: |
Only 400 samples in chain.
Multiprocess sampling (4 chains in 4 jobs)
CompoundStep
>Metropolis: [age_2]
>Metropolis: [hours]
>Metropolis: [educ]
>Metropolis: [age]
>Metropolis: [sex[T. Male]]
>Metropolis: [Intercept]
Sampling 4 chains: 100%|██████████| 3600/3600 [02:59<00:00, 20.06draws/s]
The gelman-rubin statistic is larger than 1.4 for some parameters. The sampler did not converge.
The estimated number of effective samples is smaller than 200 for some parameters.
1 | plot_traces(trace, burnin=200) |
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-47-8d29b264e93d> in <module>()
----> 1 plot_traces(trace, burnin=200)
<ipython-input-45-9c3be988e461> in plot_traces(traces, burnin)
8
9 ax = pm.traceplot(traces[burnin:], figsize=(12,len(traces.varnames)*1.5),
---> 10 lines={k: v['mean'] for k, v in pm.df_summary(traces[burnin:]).iterrows()})
11
12 for i, mn in enumerate(pm.df_summary(traces[burnin:])['mean']):
AttributeError: module 'pymc3' has no attribute 'df_summary'
NUTS sampler
Use pm.sample without specifying a particular sampling method (pymc3 will choose it automatically).
The sampling algorithm that will be used in this case is NUTS, which is a form of Hamiltonian Monte Carlo, in which parameters are tuned automatically. This is an advanced method that we hadn’t cover in the lectures, but it usually converges faster and gives less correlated samples compared to vanilla Metropolis-Hastings.
Since the NUTS sampler doesn’t require to tune hyperparameters, let’s run it for 10 times more iterations than Metropolis-Hastings.
1 | with pm.Model() as logistic_model: |
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [age_2, hours, educ, age, sex[T. Male], Intercept]
Sampling 4 chains: 65%|██████▌ | 11778/18000 [1:31:33<46:33, 2.23draws/s]
1 | plot_traces(trace) |
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-50-f3177cbb8580> in <module>()
----> 1 plot_traces(trace)
<ipython-input-45-9c3be988e461> in plot_traces(traces, burnin)
8
9 ax = pm.traceplot(traces[burnin:], figsize=(12,len(traces.varnames)*1.5),
---> 10 lines={k: v['mean'] for k, v in pm.df_summary(traces[burnin:]).iterrows()})
11
12 for i, mn in enumerate(pm.df_summary(traces[burnin:])['mean']):
AttributeError: module 'pymc3' has no attribute 'df_summary'
Estimating the odds ratio
Now, let’s build the posterior distribution on the odds ratio given the dataset (approximated by MCMC).
1 | # We don't need to use a large burn-in here, since we initialize sampling |
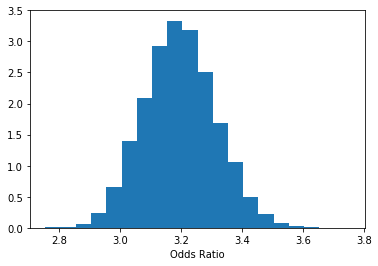
Finally, we can find a credible interval (recall that credible intervals are Bayesian and confidence intervals are frequentist) for this quantity. This may be the best part about Bayesian statistics: we get to interpret credibility intervals the way we’ve always wanted to interpret them. We are 95% confident that the odds ratio lies within our interval!
1 | lb, ub = np.percentile(b, 2.5), np.percentile(b, 97.5) |
P(2.973 < Odds Ratio < 3.435) = 0.95
1 | # Submit the obtained credible interval. |
Current answer for task 2.2 (credible interval lower bound) is: 2.973400429464148
Current answer for task 2.2 (credible interval upper bound) is: 3.4345892209585234
Task 2.3 interpreting the results
1 | # Does the gender affects salary in the provided dataset? |
Current answer for task 2.3 (does the data suggest gender discrimination?) is: Yes, we are 95% sure that a female is *less* likely to get >$50K than a male with the same age, level of education, etc.
Authorization & Submission
To submit assignment parts to Cousera platform, please, enter your e-mail and token into variables below. You can generate token on this programming assignment page. Note: Token expires 30 minutes after generation.
1 | STUDENT_EMAIL = '' |
You want to submit these numbers:
Task 1.1 (Alice trajectory): 279.93428306022463 291.67686875834846
Task 1.1 (Bob trajectory): 314.5384966605577 345.2425410740984
Task 1.2 (Alice mean): 278.85416992423353
Task 1.2 (Bob mean): 314.6064116545574
Task 1.3 (Bob and Alice prices correlation): 0.9636099866766943
Task 1.4 (depends on the random data or not): Does not depend on random seed and starting prices
Task 2.1 (MAP for age coef): 0.043482589526144325
Task 2.1 (MAP for aducation coef): 0.3621089416949501
Task 2.2 (credible interval lower bound): 2.973400429464148
Task 2.2 (credible interval upper bound): 3.4345892209585234
Task 2.3 (does the data suggest gender discrimination?): Yes, we are 95% sure that a female is *less* likely to get >$50K than a male with the same age, level of education, etc.
If you want to submit these answers, run cell below
1 | grader.submit(STUDENT_EMAIL, STUDENT_TOKEN) |
Submitted to Coursera platform. See results on assignment page!
(Optional) generating videos of sampling process
For this (optional) part you will need to install ffmpeg, e.g. by the following command on linux
apt-get install ffmpeg
or the following command on Mac
brew install ffmpeg
Setting things up
You don’t need to modify the code below, it sets up the plotting functions. The code is based on MCMC visualization tutorial.
1 | from IPython.display import HTML |
Animating Metropolis-Hastings
1 | with pm.Model() as logistic_model: |
Animating NUTS
Now rerun the animation providing the NUTS sampling method as the step argument.