Expectation-maximization algorithm
In this assignment, we will derive and implement formulas for Gaussian Mixture Model — one of the most commonly used methods for performing soft clustering of the data.
Installation
We will need 1
2
3
4
5
6
7
8
9
10
```python
import numpy as np
from numpy.linalg import slogdet, det, solve
import matplotlib.pyplot as plt
import time
from sklearn.datasets import load_digits
from grader import Grader
%matplotlib inline
Grading
We will create a grader instance below and use it to collect your answers. Note that these outputs will be stored locally inside grader and will be uploaded to the platform only after running submitting function in the last part of this assignment. If you want to make a partial submission, you can run that cell anytime you want.
1 | grader = Grader() |
Implementing EM for GMM
For debugging we will use samples from gaussian mixture model with unknown mean, variance and priors. We also added inital values of parameters for grading purposes.
1 | samples = np.load('samples.npz') |
[0.3451814 0.6066179 0.04820071]
[[-0.71336192 0.90635089]
[ 0.76623673 0.82605407]
[-1.32368279 -1.75244452]]
[[[ 1.00490413 1.89980228]
[ 1.89980228 4.18354574]]
[[ 1.96867815 0.78415336]
[ 0.78415336 1.83319942]]
[[ 0.19316335 -0.11648642]
[-0.11648642 1.98395967]]]
Reminder
Remember, that EM algorithm is a coordinate descent optimization of variational lower bound $\mathcal{L}(\theta, q) = \int q(T) \log\frac{P(X, T|\theta)}{q(T)}dT\to \max$.
E-step:
$\mathcal{L}(\theta, q) \to \max\limits_{q} \Leftrightarrow \mathcal{KL} [q(T) \,|\, p(T|X, \theta)] \to \min \limits_{q\in Q} \Rightarrow q(T) = p(T|X, \theta)$
M-step:
$\mathcal{L}(\theta, q) \to \max\limits_{\theta} \Leftrightarrow \mathbb{E}{q(T)}\log p(X,T | \theta) \to \max\limits{\theta}$
For GMM, $\theta$ is a set of parameters that consists of mean vectors $\mu_c$, covariance matrices $\Sigma_c$ and priors $\pi_c$ for each component.
Latent variables $T$ are indices of components to which each data point is assigned. $T_i$ (cluster index for object $i$) is a binary vector with only one active bit in position corresponding to the true component. For example, if we have $C=3$ components and object $i$ lies in first component, $T_i = [1, 0, 0]$.
The joint distribution can be written as follows: $p(T, X \mid \theta) = \prod\limits_{i=1}^N p(T_i, X_i \mid \theta) = \prod\limits_{i=1}^N \prod\limits_{c=1}^C [\pi_c \mathcal{N}(X_i \mid \mu_c, \Sigma_c)]^{T_{ic}}$.
E-step
In this step we need to estimate the posterior distribution over the latent variables with fixed values of parameters: $q(T) = p(T|X, \theta)$. We will assume that $T_i$ (cluster index for object $i$) is a binary vector with only one ‘1’ in position corresponding to the true component. To do so we need to compute $\gamma_{ic} = P(T_{ic} = 1 \mid X, \theta)$. Note that $\sum\limits_{c=1}^C\gamma_{ic}=1$.
Important trick 1: It is important to avoid numerical errors. At some point you will have to compute the formula of the following form: $\frac{e^{x_i}}{\sum_j e^{x_j}}$. When you compute exponents of large numbers, you get huge numerical errors (some numbers will simply become infinity). You can avoid this by dividing numerator and denominator by $e^{\max(x)}$: $\frac{e^{x_i-\max(x)}}{\sum_j e^{x_j - \max(x)}}$. After this transformation maximum value in the denominator will be equal to one. All other terms will contribute smaller values. This trick is called log-sum-exp. So, to compute desired formula you first subtract maximum value from each component in vector $X$ and then compute everything else as before.
Important trick 2: You will probably need to compute formula of the form $A^{-1}x$ at some point. You would normally inverse $A$ and then multiply it by $x$. A bit faster and more numerically accurate way to do this is to solve the equation $Ay = x$. Its solution is $y=A^{-1}x$, but the equation $Ay = x$ can be solved by Gaussian elimination procedure. You can use 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
<b>Other usefull functions: </b> <a href="https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.slogdet.html">```slogdet```</a> and <a href="https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.det.html#numpy.linalg.det">```det```</a>
<b>Task 1:</b> Implement E-step for GMM using template below.
```python
from scipy.stats import multivariate_normal
def E_step(X, pi, mu, sigma):
"""
Performs E-step on GMM model
Each input is numpy array:
X: (N x d), data points
pi: (C), mixture component weights
mu: (C x d), mixture component means
sigma: (C x d x d), mixture component covariance matrices
Returns:
gamma: (N x C), probabilities of clusters for objects
"""
N = X.shape[0] # number of objects
C = pi.shape[0] # number of clusters
d = mu.shape[1] # dimension of each object
gamma = np.zeros((N, C)) # distribution q(T)
### YOUR CODE HERE
pX_given_t = np.zeros((N, C))
for c in range(C):
model = multivariate_normal(mean=mu[c, :], cov=sigma[c, :])
pX_given_t[:, c] = model.pdf(X)
pX_given_t *= pi
gamma = pX_given_t / np.sum(pX_given_t, axis=1, keepdims=True)
return gamma
1 | gamma = E_step(X, pi0, mu0, sigma0) |
(280, 3)
Current answer for task Task 1 (E-step) is: 0.5337178741081263
M-step
In M-step we need to maximize $\mathbb{E}{q(T)}\log p(X,T | \theta)$ with respect to $\theta$. In our model this means that we need to find optimal values of $\pi$, $\mu$, $\Sigma$. To do so, you need to compute the derivatives and
set them to zero. You should start by deriving formulas for $\mu$ as it is the easiest part. Then move on to $\Sigma$. Here it is crucial to optimize function w.r.t. to $\Lambda = \Sigma^{-1}$ and then inverse obtained result. Finaly, to compute $\pi$, you will need Lagrange Multipliers technique to satisfy constraint $\sum\limits{i=1}^{n}\pi_i = 1$.
Important note: You will need to compute derivatives of scalars with respect to matrices. To refresh this technique from previous courses, see wiki article about it . Main formulas of matrix derivatives can be found in Chapter 2 of The Matrix Cookbook. For example, there you may find that $\frac{\partial}{\partial A}\log |A| = A^{-T}$.
Task 2: Implement M-step for GMM using template below.
1 | def M_step(X, gamma): |
1 | gamma = E_step(X, pi0, mu0, sigma0) |
Current answer for task Task 2 (M-step: mu) is: 2.899391882050384
Current answer for task Task 2 (M-step: sigma) is: 5.9771052168975265
Current answer for task Task 2 (M-step: pi) is: 0.5507624459218775
Loss function
Finally, we need some function to track convergence. We will use variational lower bound $\mathcal{L}$ for this purpose. We will stop our EM iterations when $\mathcal{L}$ will saturate. Usually, you will need only about 10-20 iterations to converge. It is also useful to check that this function never decreases during training. If it does, you have a bug in your code.
Task 3: Implement a function that will compute $\mathcal{L}$ using template below.
$$\mathcal{L} = \sum_{n=1}^{N} \sum_{k=1}^{K} \mathbb{E}[z_{n, k}] (\log \pi_k + \log \mathcal{N}(x_n | \mu_k, \sigma_k)) - \sum_{n=1}^{N} \sum_{k=1}^{K} \mathbb{E}[z_{n, k}] \log \mathbb{E}[z_{n, k}]$$
1 | def compute_vlb(X, pi, mu, sigma, gamma): |
1 | pi, mu, sigma = pi0, mu0, sigma0 |
Current answer for task Task 3 (VLB) is: -1213.973464306017
Bringing it all together
Now that we have E step, M step and VLB, we can implement training loop. We will start at random values of $\pi$, $\mu$ and $\Sigma$, train until $\mathcal{L}$ stops changing and return the resulting points. We also know that EM algorithm sometimes stops at local optima. To avoid this we should restart algorithm multiple times from different starting positions. Each training trial should stop either when maximum number of iterations is reached or when relative improvement is smaller than given tolerance ($|\frac{\mathcal{L}i-\mathcal{L}{i-1}}{\mathcal{L}_{i-1}}| \le \text{rtol}$).
Remember, that values of $\pi$ that you generate must be non-negative and sum up to 1. Also, $\Sigma$ matrices must be symmetric and positive semi-definite. If you don’t know how to generate those matrices, you can use $\Sigma=I$ as initialization.
You will also sometimes get numerical errors because of component collapsing. The easiest way to deal with this problems is to simply restart the procedure.
Task 4: Implement training procedure
1 | import math |
1 | best_loss, best_pi, best_mu, best_sigma = train_EM(X, 3) |
Current answer for task Task 4 (EM) is: -1063.811767605055
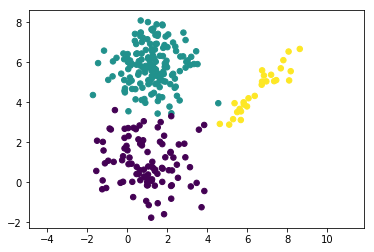
If you implemented all the steps correctly, your algorithm should converge in about 20 iterations. Let’s plot the clusters to see it. We will assign a cluster label as the most probable cluster index. This can be found using matrix $\gamma$ computed on last E-step.
1 | gamma = E_step(X, best_pi, best_mu, best_sigma) |
Authorization & Submission
To submit assignment parts to Cousera platform, please, enter your e-mail and your token into variables below. You can generate the token on this programming assignment page. Note: Token expires 30 minutes after generation.
1 | STUDENT_EMAIL = '' |
You want to submit these numbers:
Task Task 1 (E-step): 0.5337178741081263
Task Task 2 (M-step: mu): 2.899391882050384
Task Task 2 (M-step: sigma): 5.9771052168975265
Task Task 2 (M-step: pi): 0.5507624459218775
Task Task 3 (VLB): -1213.973464306017
Task Task 4 (EM): -1063.811767605055
If you want to submit these answers, run cell below
1 | grader.submit(STUDENT_EMAIL, STUDENT_TOKEN) |
You used an invalid email or your token may have expired. Please make sure you have entered all fields correctly. Try generating a new token if the issue still persists.